从 roboflow 标注数据之后,导出的 YOLO v5 PyTorch 配置文件 YAML 格式 (TXT annotations and YAML config used with YOLOv5),里面的文件路径非常不友好,每次都需要修改调整。
特别是要上传到 colab 训练,在 google drive 里在线修改 yaml 文件非常麻烦。因为为了防止
Exception: Dataset not found
我都是用的绝对路径。
我的疑问是,是否存在一种路径组织方式可以同时满足本地和线上 (colab / kaggle),不需要来回改本地绝对路径。
周末陪我妈在毓璜顶医院排队做 CT 的时候,我翻看公众号上关于 yolo v5 的一些使用经验,无意发现原来 yolo v5 自带了一些标注好的训练数据,当然只是配置文件,里面包含了对应的下载地址。以 GlobalWheat2020.yaml 为例,里面有个 path 参数,其定义了数据文件目录与 train.py 的相对路径,这样就方便多了。
合理的数据文件夹存放目录
与 yolov5 代码平级的目录 datasets,然后 datasets 目录下是不同的数据集,例如:GlobalWheat2020,如下图的结构
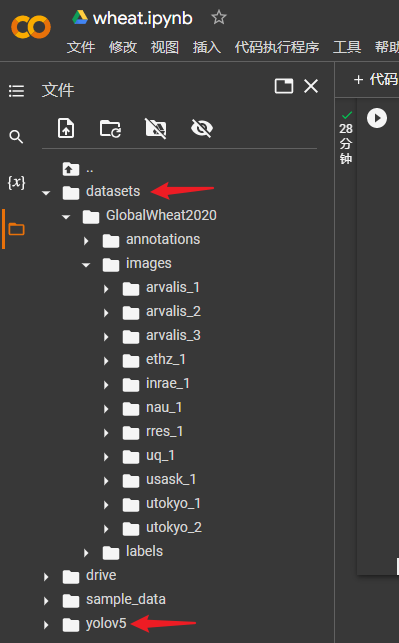
path 里使用相对路径即可。
path: ../datasets/some_app # 相对 train.py 的路径
train: some_dir # 相对 path 的路径
test: some_dir
val: some_dir
下面是两种格式的对比,显然第二种方式更合理。
roboflow 导出的 yaml 格式
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 1
names: ['elephant']
yolo v5 自带的 GlobalWheat2020.yaml 格式
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
# Example usage: python train.py --data GlobalWheat2020.yaml
# parent
# ├── yolov5
# └── datasets
# └── GlobalWheat2020 ← downloads here (7.0 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/GlobalWheat2020 # dataset root dir
train: # train images (relative to 'path') 3422 images
- images/arvalis_1
- images/arvalis_2
- images/arvalis_3
- images/ethz_1
- images/rres_1
- images/inrae_1
- images/usask_1
val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
- images/ethz_1
test: # test images (optional) 1276 images
- images/utokyo_1
- images/utokyo_2
- images/nau_1
- images/uq_1
# Classes
names:
0: wheat_head
微信关注我哦 👍

我是来自山东烟台的一名开发者,有感兴趣的话题,或者软件开发需求,欢迎加微信 zhongwei 聊聊, 查看更多联系方式