在监督学习 (supervised learning)中,机器学习算法的目标是通过检验一堆 examples, 建立一个模型 (model),以最小化 loss。
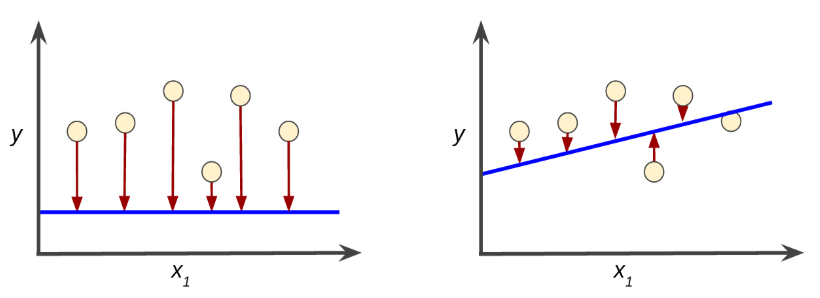
这个 loss,我的理解是,设置一个阈值,当曲线与 example 点的偏差小于某个差值时,表示这个 example 可以接受,否则则是 loss。训练出的最佳 model 即是能接受最多的 examples 的 model.
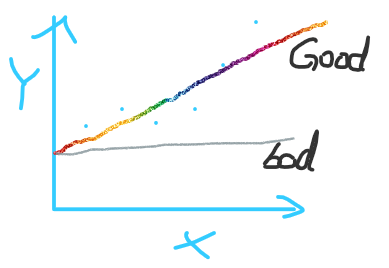
假设 x 轴代表博客文章数,y 轴代表日 UV,那么 Good 曲线比 bad 曲线的预测效果更好。
所以评判一个训练的出的 model 的好坏,就是判断其对 examples 的 loss 的多少。Loss 越少说明预测效果越好;反之,越差。
预测效果好坏的评判方法 - loss function
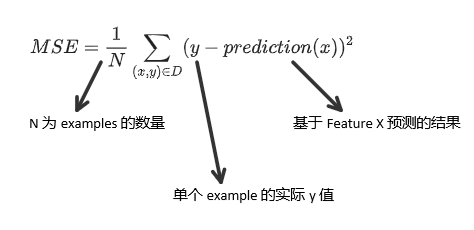
D 为 data set, 即一堆 labeled examples 的集合。
MSE = Mean Square Error 平方误差均值。MSE 是一种常见的 loss function,但并不是唯一的 loss function。
微信关注我哦 👍

我是来自山东烟台的一名开发者,有感兴趣的话题,或者软件开发需求,欢迎加微信 zhongwei 聊聊, 查看更多联系方式