目标
- 了解 InfluxDB 2.0 写入数据格式 Line protocol
- Influx 命令行写入
- 如何查看写入的数据
- TODO: Golang SDK 写入
写入数据格式 Line protocol
https://docs.influxdata.com/influxdb/v2.0/reference/syntax/line-protocol/
格式:
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]] <field_key>=<field_value>[,<field_key>=<field_value>] [<timestamp>]
这样看,还是太抽象,很难直观的区分 measurement, tag_key, field_key 的使用规范。
找个例子看会直观一些,例如官方提供的空气传感器的数据示例:
https://github.com/influxdata/influxdb2-sample-data/blob/master/air-sensor-data/air-sensor-data.lp
lp 是 Line protocol 的缩写
airSensors,sensor_id=TLM0100 temperature=71.18922021239435,humidity=35.096794192432846,co=0.49012238573499495 1623288483000000000
- 这里的 measurement 是 airSensors, 感觉这样写跟 bucket 差不多了。。。意思是一个 bucket 中,可能既有空气传感器、又有水质传感器、压力传感器?
- tag_key 为 sensor_id, 即传感器 ID
- field_key: 温度,湿度,CO 浓度
- 最后是时间戳。默认是纳秒 nanoseconds (ns)。也支持其他精度,但是需要加上精度标识,微秒(us)、毫秒(ms)、秒(s)。
设计原则 - InfluxDB schema design
https://docs.influxdata.com/influxdb/v2.0/write-data/best-practices/schema-design/
- 需要查询的 keyword 放入 tag 中,例如传感器 ID,设备 ID。因为 tag 是被索引的,而 field 不会。
- tag 数量可控。如果建立过多索引,写入、查询性能都会下降。
- tag_key, field_key 避免使用相同的名字
Influx 命令行写入
例如,我想将上面的数据示例写入我本地安装的 Influx DB 2.0:
- 组织名:sunzhongwei.com
- bucket: oxygen
influx write \ -b oxygen \ -o sunzhongwei.com \ 'airSensors,sensor_id=TLM0100 temperature=71.18922021239435,humidity=35.096794192432846,co=0.49012238573499495 1623288483000000000'
参考:
https://docs.influxdata.com/influxdb/v2.0/write-data/developer-tools/influx-cli/
同时,也支持 csv 以及 txt (lp 数据行) 这两种批量格式。
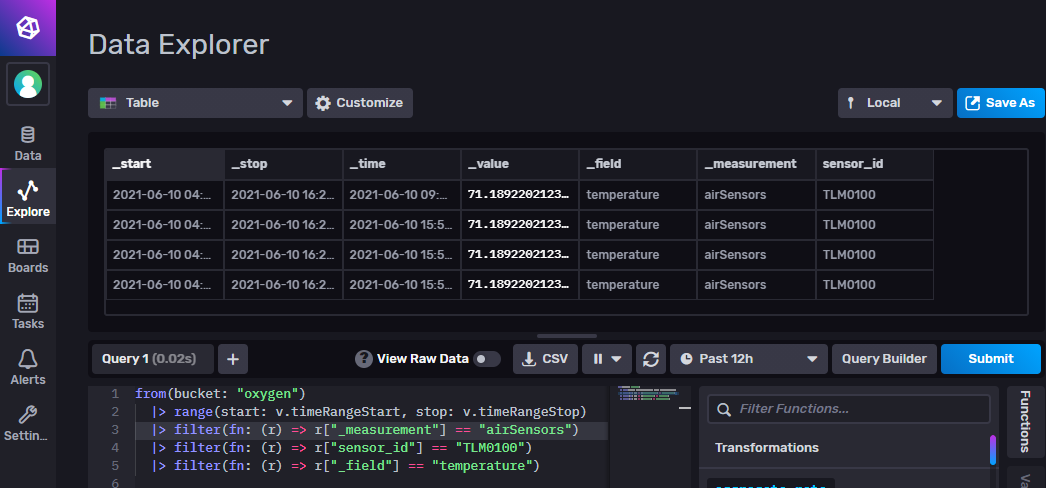
如何查看写入的数据
最简单直观的方式是访问 InfluxDB UI
http://localhost:8086/
选择 Explore 菜单
输入查询语句:
from(bucket: "oxygen")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "airSensors")
|> filter(fn: (r) => r["sensor_id"] == "TLM0100")
|> filter(fn: (r) => r["_field"] == "temperature")
这里的 v.timeRangeStart 和 v.timeRangeStop 代表时间区间下拉框选中的时间段,例如
Past 12h, 即过去 12 小时。效果如图:
关于作者 🌱
我是来自山东烟台的一名开发者,有感兴趣的话题,或者软件开发需求,欢迎加微信 zhongwei 聊聊,或者关注我的个人公众号“大象工具”, 查看更多联系方式